Modular Code for Modular Hardware w/ Metaprogramming
Remote Procedure Calls (RPCs) are a great pattern for interfacing with embedded codes - especially when they replace serial string parsers - but they can be tiresome to generate by-hand. In this post, I demo an automatic RPC generator that pulls function signatures directly out of compiled code on embedded devices, and rolls up python interfaces for them.
Automated RPCs and Templated Proxy Classes
A few weeks ago I finally finished the automatic Remote Procedure Call (RPC) class for arduino, which lets us automatically build interfaces for embedded devices using most basic programming concept: the function call. We write a function on the device, we tag it with an RPC macro, and it becomes available to call over the network.
This post is about the other half of that workflow: generating software interfaces - “proxies” - that represent embedded devices in higher level programming languages. In particular, previous work required that we use the auto RPC pattern within a standalone code editor - in this work we can deploy the modules more fluidly.
I’ve been interested in this kind of work because I think that Open Hardware doesn’t have a great set of tooling for systems integration, and I think that good, modular interfaces can lead us into the commons of Open Hardware.
Automated RPCs in the Wild
So… what is this for? Well, for one fun example, we have this little robot xylophone project that I finished with Quentin. It runs hardware / firmware modules of my design, whose APIs are exposed using the system I’ve described here. Quentin, the CBA’s resident CV lover, used those interfaces to stack an interactive controller w/ a camera and MIDI keyboard onto the machine:
Building good interfaces to our hardware helps other developers build applications on top of what we’ve done - i.e. this robo-xylophone serves an API that Quentin used to turn it into a MIDI keyboard output device (including CV to track finger position to preempt the key presses).
I use these also to build bigger systems, like this FDM printer that is collecting data on printing physics while-it-prints. Doing this in embedded alone would be obviously cumbersome, but being able to partition between big-compute (to collect and analyse) and embedded-compute (to listen and actuate) makes it pretty easy.
Good embedded interfaces also helps us de-clutter big systems, like this FFF 3D printer that captures process data while it operates.

The printer’s controller is mostly built in python, using interfaces to hardware devices built using the strategy described in this post. Devices are simple and relatively stateless: motors know how to follow spline trajectories (but don’t manage i.e. acceleration control), sensors can generate readings, but high level program state is managed and modified without editing firmware.
For a clear example of digital twinning, when we virtualize our controllers, it becomes also very easy to build parseable virtual models of them, and pipe data back and forth, i.e. to debug kinematics:
In the world beyond our desks at the CBA, many new off-the-shelf scientific devices already serve python APIs, making the language a productive site for systems integration; it’s the party that everyone is already attending. We want to be able to quickly bring our own ad-hoc systems to the same venue, and share tools with device OEMs, whose costs are increased by developing these interfaces. We discussed all of these bottlenecks at some length in April 2024 at Nadya’s POSE Workshop at the University of Washington.
Replacing Serial String Parsers with RPCs and Proxies
One of the most painful, and most often re-engineered components of embedded projects is the serialport parser: a layer that connects to a device and writes / reads characters to the port. In many instances, these characters are ASCII string encodings, and developers craft interfaces on either end of the port (one in embedded, one in i.e. python, processing, or javascript) to develop whatever interconnect they need: for data collection, for sending commands to an embedded device, etc etc.
This pattern is all over the place, but it’s cumbersome to build and maintain, it sucks space in Flash, and it’s hard to document. I complained about these over here as well.
Replacing this with object oriented hardware is an ongoing effort in my research group at the CBA; see Ilan and Nadya’s theses. What I’m writing about here is basically an extension of modular-things, which I started with Quentin Bolsee and Leo McElroy.
The gist is that we turn devices into software objects that I call proxies; i.e. the stepper motor that controls the x-axis of a machine becomes a proxy object called stepper_x that has multiple rpcs attached. In our program, and then we can write higher level codes with that, like:
# for example, with a nice low-level API to a motor, we can write
# higher-level routines (like homing) in a language that is easier
# to inspect and edit (like python)
# meaning less firmware updates, more flexibility, etc:
# our interface (next code snippet)
import SimpleStepper
# we instantiate each instance by passing in a device name
# the dname is a circuit-specific string; this is basically an addressing step
stepper_x = SimpleStepper(osap, "stepper_x")
def home_x_motor():
# turn the motor on and head towards the switch
await stepper_x.set_current_scale(0.25)
await stepper_x.set_velocity(-10.0)
# wait until the limit is hit,
while (await stepper_x.get_limit_state()) != True:
await asyncio.sleep()
await stepper_x.stop()
The pattern is useful mainly because embedded development is hard(er) than development in high level languages like python. We still need embedded codes to manage the really high-speed, low-latency actions required for i.e. motor control (for example, a stepper motor needs to ‘tick’ at nearly 100kHz), but it’s a pain to also assemble complex logic in embedded cpp. By bundling the device as a software object, we can interact with it at a high level without sweating the details. If we develop those device APIs well, we can re-use modular hardware across a number of projects.
async codes are a particularely useful tool in this regard: we can issue requests to multiple devices at once, and wait for them all to complete, before moving on to the next action for our system. Doing this in embedded code alone basically requires an RTOS (or some similar homebrew RTOS-like scheduler), but we get it for free in python.
What’s in a Proxy
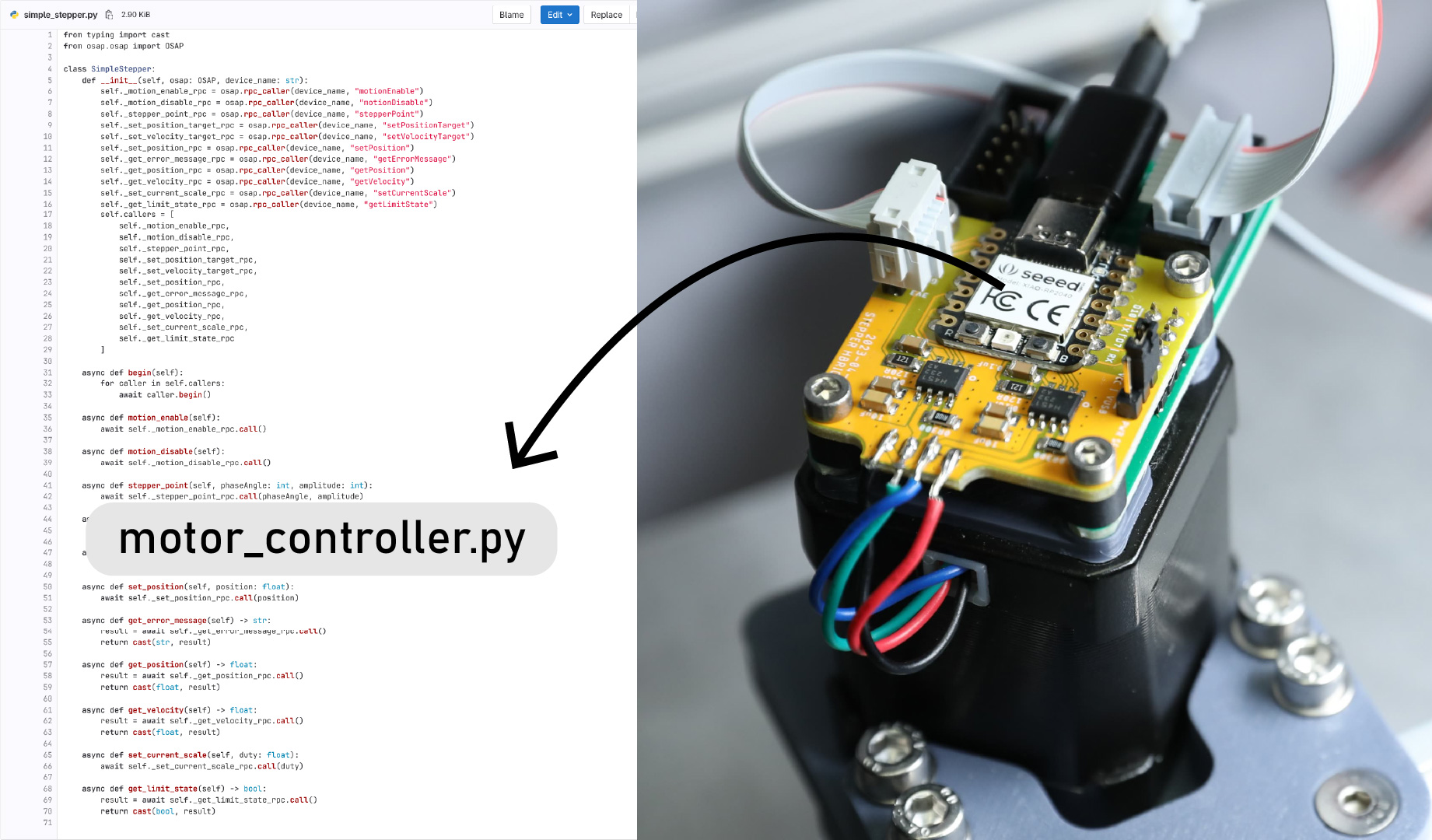
Writing proxies is straightforward: we build one rpc_caller for each function, which gets network addresses to the rpc_implementation that we wrote previously in firmware. The rpc_caller does all the work of serializing data, sending it to the right network coordinates, and deserializing return values. The proxy simply wraps all of these into a class that represents the device, and presents python-native function names and type hints.
This might look a little clunky, but don’t worry because we don’t need to write it by hand.
from typing import cast
from osap.osap import OSAP
class SimpleStepper:
def __init__(self, osap: OSAP, device_name: str):
self._set_position_target_rpc = osap.rpc_caller(device_name, "setPositionTarget")
self._set_velocity_target_rpc = osap.rpc_caller(device_name, "setVelocityTarget")
self._set_position_rpc = osap.rpc_caller(device_name, "setPosition")
self._get_error_message_rpc = osap.rpc_caller(device_name, "getErrorMessage")
self._get_position_rpc = osap.rpc_caller(device_name, "getPosition")
self._get_velocity_rpc = osap.rpc_caller(device_name, "getVelocity")
self._set_current_scale_rpc = osap.rpc_caller(device_name, "setCurrentScale")
self._get_limit_state_rpc = osap.rpc_caller(device_name, "getLimitState")
self.callers = [
self._set_position_target_rpc,
self._set_velocity_target_rpc,
self._set_position_rpc,
self._get_error_message_rpc,
self._get_position_rpc,
self._get_velocity_rpc,
self._set_current_scale_rpc,
self._get_limit_state_rpc
]
async def begin(self):
for caller in self.callers:
await caller.begin()
async def set_position_target(self, position: float, maxVelocity: float, maxAccel: float):
await self._set_position_target_rpc.call(position, maxVelocity, maxAccel)
async def set_velocity_target(self, velocity: float, maxAccel: float):
await self._set_velocity_target_rpc.call(velocity, maxAccel)
async def set_position(self, position: float):
await self._set_position_rpc.call(position)
async def get_error_message(self) -> str:
result = await self._get_error_message_rpc.call()
return cast(str, result)
async def get_position(self) -> float:
result = await self._get_position_rpc.call()
return cast(float, result)
async def get_velocity(self) -> float:
result = await self._get_velocity_rpc.call()
return cast(float, result)
async def set_current_scale(self, duty: float):
await self._set_current_scale_rpc.call(duty)
async def get_limit_state(self) -> bool:
result = await self._get_limit_state_rpc.call()
return cast(bool, result)
Hardware systems can be complex; when we have to remember what all of our RPC function names are while we’re programming, we can easily make mistakes. The interface class basically gives our IDE the ability to auto complete and auto correct for us, and the type-hints are (IMO) the best form of documentation we can ask for.

Proxies are invaluable tools when programming, for the simple utility of providing auto-complete and type hints in an IDE. We can also name each proxy to make sense of which device we are addressing, making semantic sense in big systems with many devices.
The ‘Metaprogramming’
So, the proxyy is rad, but writing it is a time suck - especially if we’re looking at someone else’s firmware. But, all of the information we need to write the interface is already available via the auto-rpc class - that is, the embedded device knows what its functions are called, what their type signatures are and so on, and we can query whenever they are connected to our network in order to learn these data.
To turn those function signatures into callable proxy classes, I used jinja - a python package for string templating. It’s not dissimilar to liquid, which Jekyll uses (and which this site is built with). String templating is a pattern I became familiar with thanks to Leo, who showed me lit-html a while ago and got me thinking about this notion of programs writing programs.
This is what I mean by ‘metaprogramming’ - although I think this is like soft-core metaprogramming - the really wild stuff in this domain is i.e. programs that optimize themselves at runtime, etc.
Jinja can look kind of gnarly, since we are making statements (in jinja) about making statements (in python), here’s the code that writes modules:
from typing import cast
from osap.osap import OSAP
class {{ class_name }}:
def __init__(self, osap: OSAP, device_name: str):
{% for func in signatures %}self.{{ func.pythonic_name }}_rpc = osap.rpc_caller(device_name, "{{ func.name }}")
{% endfor %}self.callers = [
{% for func in signatures %}self.{{ func.pythonic_name }}_rpc{% if not loop.last %},
{% endif %}{% endfor %}
]
async def begin(self):
for caller in self.callers:
await caller.begin()
{% for func in signatures %}async def {{ func.pythonic_name }}(self{% for arg in func.args %}, {{ arg.name }}: {{ arg.type_name }}{% endfor %}){% if func.return_type == "void" %}{% else %} -> {{ func.return_type }}{% endif %}:
{% if func.return_type == "void" %}{% else %}result = {% endif %}await self.{{ func.pythonic_name }}_rpc.call({% for arg in func.args %}{{ arg.name }}{% if not loop.last %}, {% endif %}{% endfor %}){% if func.return_type == "void" %}{% else %}
return cast({{ func.return_type }}, result){% endif %}
{% endfor %}
To use these, we connect all of our embedded devices, and then query them for their function signatures, device names, etc. We then feed that data into this structure, and write the output as a .py file.
Naming and Case Conventions
At this point our system is authored in two languages - probably cpp (in the embedded device, or rust if we get our act together and learn that new language that everyone is on about…), and in python, where our interface and the rest of our high-level system lives.
As a minor annoyance, style is language dependent: javaScript folks tend to prefer camelCase, python’s pep8 advocates for ClassNames and function_names, and cpp is something of a free-for-all.
Mostly for Quentin’s sake, I added some utilities to translate betwixt them all - so if we use camelCase functions in the embedded device, they are served to us as snake_case functions in python.
Actually, ChatGPT wrote these utilities - regex was always for robots anyways.
def to_camel_case(name):
# Split the string by non-alphanumeric characters
words = re.split(r'[^a-zA-Z0-9]', name)
# Capitalize the first letter of each word and join them together
camel_case_name = ''.join(word.capitalize() for word in words if word)
return camel_case_name
def to_snake_case(name):
# Replace dashes with underscores
name = name.replace('-', '_')
# Insert underscores before capital letters (considering initial caps and acronyms)
name = re.sub(r'(?<!^)(?=[A-Z])', '_', name)
# Convert the whole string to lowercase
return name.lower()
Writing a Boilerplate main.py
Finally, the code generates an example of how one would deploy these modules - the main.py - this is of course optional, but I thought it would be nice to have as a quick-start tool. It initializes the proxy objects, connects the networking drivers, and wraps it all in async nuts and bolts.
import asyncio
import traceback
from osap.bootstrap.auto_usb_serial.auto_usb_serial import AutoUSBPorts
from osap.osap import OSAP
# import each interface / device proxy
from proxies.stepper_cl_d51_proxy import StepperClD51Proxy
async def main():
try:
# init networking service
osap = OSAP("auto_modules_main")
loop = asyncio.get_event_loop()
loop.create_task(osap.runtime.run())
# connect via usb
ports = AutoUSBPorts().ports
for port in ports:
osap.link(port)
# collect an image of the system
system_map = await osap.netrunner.update_map()
system_map.print()
# instantiate each of our modules,
stepper = StepperClD51Proxy(osap, "stepper_cl")
# and set each up: this block additionally verifies that proxies
# are matched to implementation signatures discovered at runtime
await stepper.begin()
# insert test code below...
#
#
#
except asyncio.CancelledError:
print("bailing...")
except Exception as err:
print(traceback.format_exc())
finally:
# put shutdown codes here,
# i.e. powering down current sources, etc...
if __name__ == "__main__":
asyncio.run(main())
The resulting workflow is one of the most productive tools I have written for myself during my PhD - we do:
- (1) tag some functions in your embedded device using a one-line macro
BUILD_RPC(func, arg_names) - (2) connect the device to a PC and run a small script, that:
- (2.1) reads function signatures from the device
- (2.2) writes a
device_proxy.pyfor each embedded device, and amain.pyfile that initializes and connects to them all
- (3) add whatever test codes to the
main.pyfile, - (4) run the
main.py… modify it, move the interface to some other project, etc etc
The bottom line for me is that I don’t have to hand-craft interfaces to embedded devices, even the ones that I am actively developing: when I add a new function to a device, or a new device to a system, I simply re-run these scripts and get back to development. Device names, function names and types, all stay consistent, and matched to hardware implementation. For a mild dyslexia sufferer / maker of small mistakes, this has vastly improved my development cycles.
Future Efforts: Protocols, Standards
Like I mentioned, the motivation for these types of systems is to enable a commons of open hardware. One of the current impediments to open hardware’s success is that, while many contributions exist (devices), we still struggle to make systems out of those building blocks.
Probably the best integration system for open hardware is still Arduino’s ecosystem, but it is fraught with strange gotchas - i.e. while combining many sensors into one project, we might run out of I2C resources (address space, or time)… and as we add parts and libraries, we eventually eat up all of the RAM and CPU cycles available on our project’s main microcontroller.
With strategies like this one - where we combine many devices by networking them together - we can scale systems more rapidly. However, we want to minimize the burden on device developers and on systems integrators. If I am going to use a circuit module that someone else designed, I should not have to understand how their firmware or their build system works in order to deploy it in my own application. I want to plug and play.
The proposal here is that device firmwares themselves can contain all of the information required to interface to the device, in a semantically meaningful way, using off-the-shelf programming paradigms. We want to be able to extract that information from a single source of truth and use it natively.
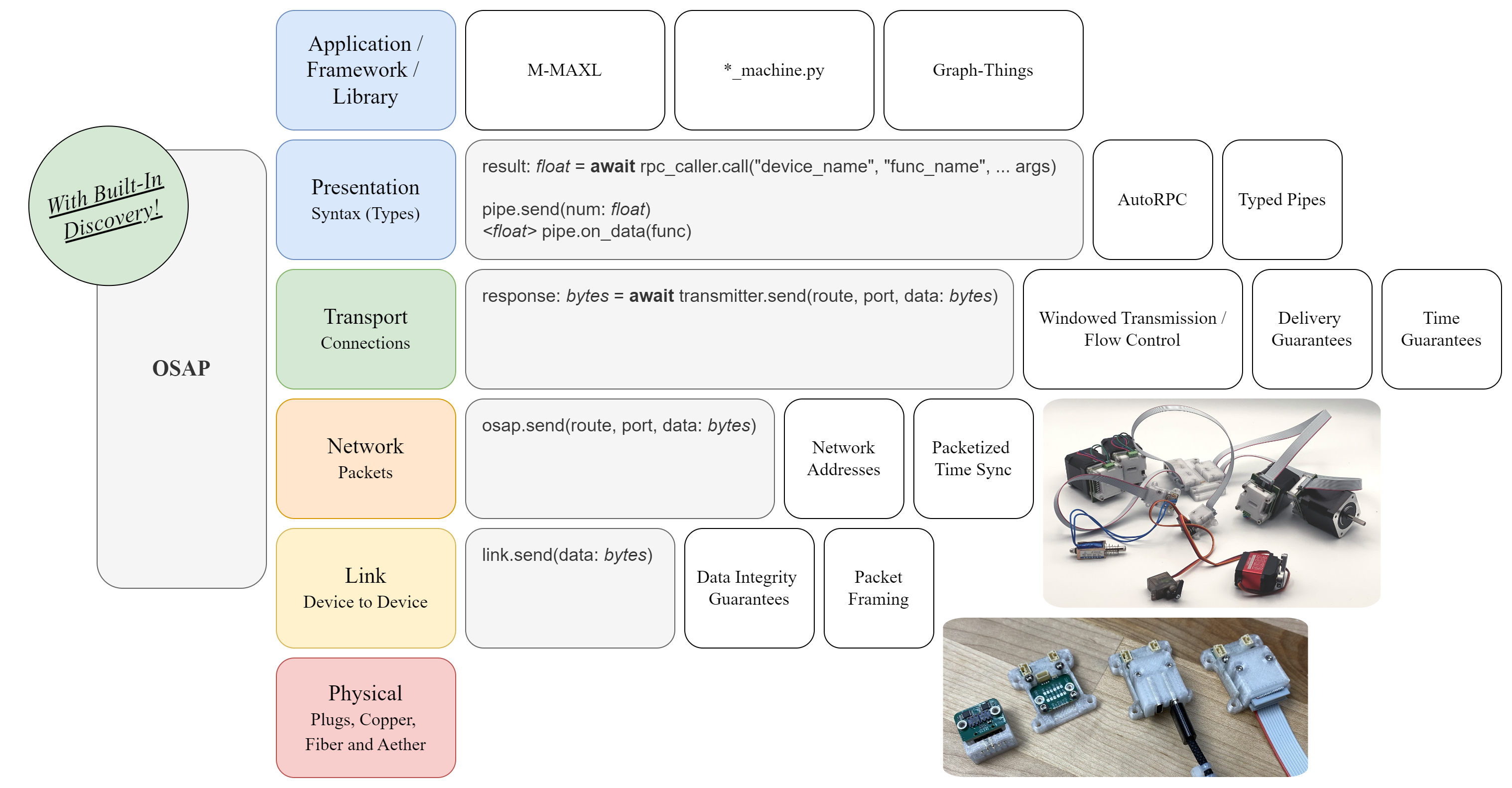
To improve systems integration in open hardware (and beyond), we should make more explicit use of an OSI model for mechatronic devices. The strategies discussed in this post take place in the presentation layer (near the top); they concern how we represent data and devices to application developers. We also need to work on the rest of the stack.
Besides the networking step (where many people are already sticking USB, BLE or i.e. CAN interfaces on their devices), we still need to make sense of the packets sent between our applications and our devices - and from device to device. Doing so across open hardware projects would be an effort in standards development: how to encode function signatures, type signatures, and serialize / deserialize data transfers. While I am independently working on each of these things, doing it on my own is not really a viable path towards such a standard - in the future we will all need to agree on their shapes, forms and styles.
Some Discussion
I am in no way proposing this as a be-all end-all solution, but I think it’s an interesting step, and has been hugely productive for me personally - so I wanted to discuss it.
I think that interesting future work would address the issue of versioning and duplication: i.e. a system containing two of the same devices, but with firmwares of variable lineage. There is also still a burden of documentation: functions should probably contain docstrings as well, but storing those all in a microcontroller seems cumbersome - instead, they could perhaps return URIs to expanded docs served online, or some mixture of both.
The approach also requires really good serialization / deserialization routines, and can lead to lots of manual type-checking, since embedded devices tend to have less flexible native types than i.e. python, so strange things might happen when we send i.e. python’s native int64 into a function that declared a uint8_t argument.
This approach is also of the flavour where we basically “throw it all into python” and then hope that there’s enough performance there, but .py is not a terribly performant language, so for the integration of high-speed systems, we probably need a better low-level tool that lets us avoid operating systems entirely. To that end, I have been developing graph based tools that let us pipe data directly between embedded devices (but visualize and edit configs at a high level). If I survive this PhD there will be more on that later.
In the end, what we want is for things to ‘just work’ - we want to build the complex bits, the high level controllers. No-one should be out here re-engineering motor controllers and motion systems just so that they can do science with a robot, etc etc. Systems integration is the stuff that plugs individual engineers into the world’s economies and hooks their contributions up to teams, firms, and society, man … we should spend more time making it beautiful, functional and fun.
« MUDLink: a Modular UART Duplex Link
A Thesis Proposal! »